이번에는 JDBC를 통해서 DBMS와 JAVA를 연동해보겠다.
내부 동작 구조와 JDBC
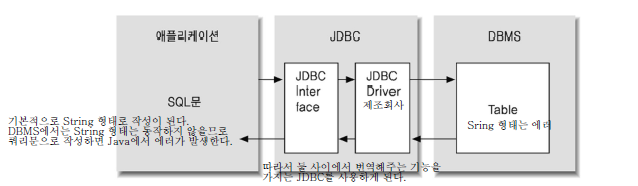
JDBC는 java사에서 DB와 연동 할 수 있게 만든 것으로 위와 같은 내부구조를 가진다. 하지만 JDBC는 바로 사용할 수 없고 interface만 구성되어 있고 동작은 overriding해서 사용해야 한다. 그 이유는 모든 DBMS가 같은 구조로 동작되지 않기 때문이다. 따라서 해당 DBMS에 맞게 재정의 해서 사용해야 한다.
내부 구조를 살펴보면 애플리케이션 즉, eclipse 와 같은 java ide에서 sql문이 String 형태로 날아갈 것이다. 그럼 이를 DBMS에서 사용할 수 있게 번역의 기능을 하는것이 JDBC이다. 이정도 구조만 알아도 이해하기엔 무리 없을 것이다.
기본적으로 프로젝트나 여러가지 상황에서 주로 동적 쿼리를 사용하는 경우가 많아 동적 쿼리를 기준으로 작성하였다.
정적 쿼리를 작성하고 싶은 경우 PreparedStatement 대신 일반 Statement를 사용하고 StringBuffer에 올바른 쿼리문을 작성하면 된다.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class UserDB {
public static void main(String[] args) {
StringBuffer sql = new StringBuffer();
sql.append("insert into CGVUSER ");
sql.append("values(?,?,?,?,sysdate)");
Connection con = null;
PreparedStatement pstmt = null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
con = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521/XEPDB1","test","test");
pstmt = con.prepareStatement(sql.toString());
pstmt.setString(1, "id");
pstmt.setString(2, "password");
pstmt.setString(3, "저팔계");
pstmt.setString(4, "남자");
int result = pstmt.executeUpdate();
System.out.println(result+"개의 행이 추가되었습니다.");
}catch (ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}finally {
try {if(pstmt!=null) pstmt.close();} catch(SQLException e) {}
try {if(con!=null) con.close();} catch(SQLException e) {}
}
}
}
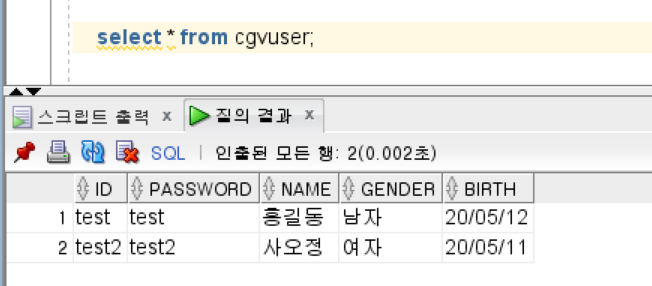
위와 같이 INSERT 구문이 잘 동작하는것을 볼 수 있다.
'DB(DataBase) > Oracle' 카테고리의 다른 글
| [DB] Oracle(오라클)의 기본적인 쿼리(CRUD) (0) | 2020.05.12 |
|---|---|
| [DB] Oracle의 초기설정 (0) | 2020.05.12 |